By Picturepark Communication Team • Mar 17, 2014
This post illustrates how Picturepark Adaptive Metadata technology can be used to change an asset’s metadata schema throughout the content’s lifecycle, and in response to unforeseen events.
Before we get into the details of how this works, let’s consider the benefits of being able to “animate” metadata schemas over time:
- Metadata schemas always show relevant metadata
- Metadata schemas can be smaller because only required information is available
- Metadata schemas can be more precise because compromise isn’t needed
This post is follows a single piece of content throughout a fictional lifecycle, from creation to archive. As time passes and different circumstances arise, the metadata schema adapts. Users always see what they need to see, so no one is confused and everything makes sense. Note that the metadata fields and content classes used in these examples have been added to Picturepark by the author for this example.
Before any lifecycle has been assigned, the asset shows no metadata fields. (Note that in a real life scenario, you would likely still have standard DAM metadata values, like Title, Description, File Size, etc. For this example, those fields have been removed.)
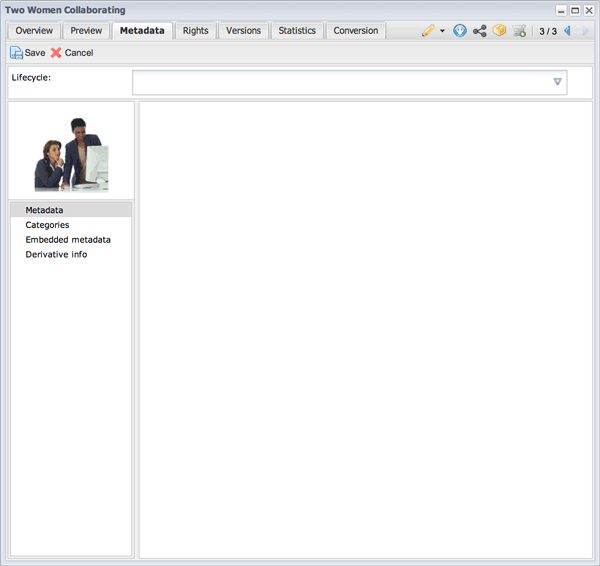
A newly uploaded asset before any lifecycle classes have been added. If you want to avoid having no lifecycle classes applied, apply a default class during the upload or have the uploading user choose an appropriate class.
Lifecycle: Draft
When draft content is first added to the DAM, its metadata schema must reflect Editor, Instructions, Expected By date and other fields required for tracking development. By assigning the Draft class to this asset, we get those fields.
Lifecycle Stage 1: We add the Draft lifecycle class to the asset. Three metadata fields appear. We use these fields to assign the asset to a worker and define the work to be done.
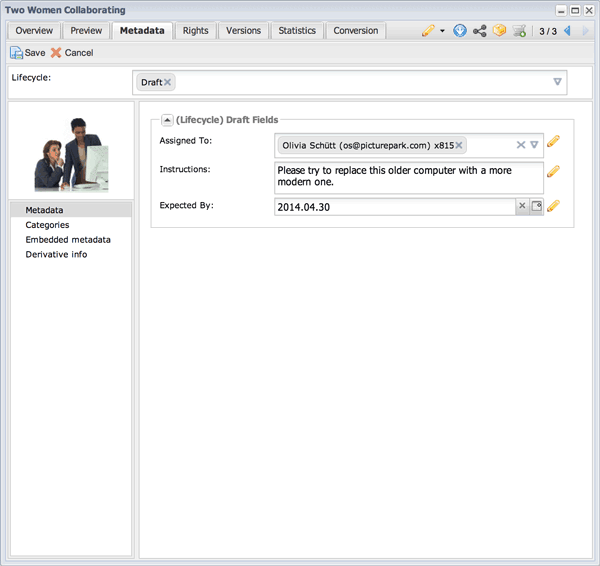
When the Draft class is assigned to this asset, the pertinent fields appear to users who should see them. Granular permissions determine who can see and edit every field in Picturepark, so you can always hide what certain users shouldn’t see.
Lifecycle: Review
Eventually, the content is ready for review. This will require some new metadata fields but we don’t want to lose the Draft metadata. Fortunately, an asset can be assigned to many different classes. So you can simply add the Review class to get the metadata fields you want, without affecting the fields provided by the Draft class.
Lifecycle Stage 2: Edits have been made, so the content is ready for review. We add the Review lifecycle class to the asset. We use the three fields that appear to indicate that the content is under review, and to let users know who’s in charge of the review and when it will be complete. (Notifications can be configured to alert interested users when the Review Complete field has been checked.)
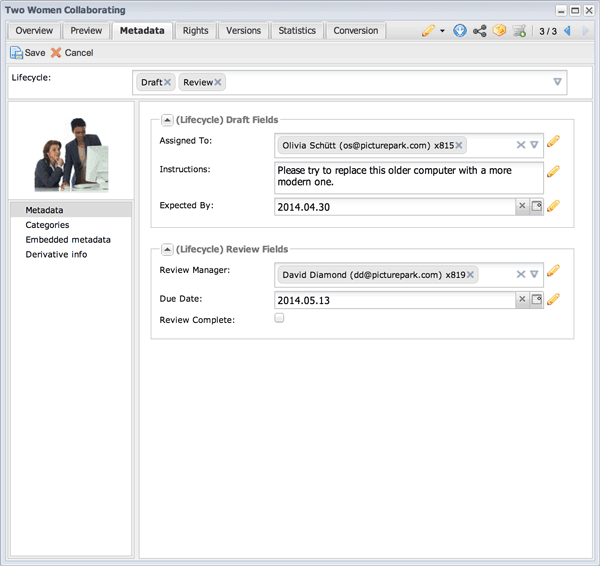
When the Review class is added to the asset, the Review fields appear to permitted users. Note that the Picturepark Review Manager can be used to actually conduct the review. These fields are used only for reporting status.
Lifecycle: Release
Once the content has been approved for release, the metadata schema must be adapted to serve the needs of regular users of the DAM. This is a good time to apply a class that’s specific to the content type so you can get all the metadata values you need. This is also a good time to remove the Draft and Review classes because the metadata fields they provide are no longer needed. (You can keep them indefinitely, if you prefer.)
Lifecycle Stage 3: The asset has been approved for use, so we remove the Draft and Review lifecycle classes and add the Release lifecycle class. The metadata fields provided by the Draft and Review classes are removed, which is fine because we no longer need them. Three new fields appear. Two of the new fields have been configured to take advantage of Picturepark controlled vocabularies to make metadata input faster and more accurate.
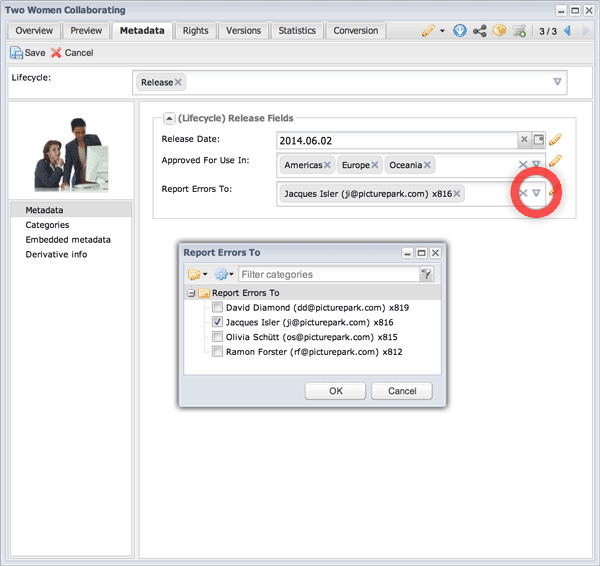
Classes can be added and removed by permitted users at any time. So it takes only a moment to completely restructure the content’s metadata schema. Note how the way in which Picturepark supports controlled vocabularies makes it easy to make choices.
Lifecycle: Social Sharing
If you’d like to provide default tweets or messages for social sharing, you can provide those with a class too.
Lifecycle Stage 4: To make it easier for users to leverage the content across social media, we add the Social Share lifecycle class to the asset and provide sharing content into the new fields that appear. The share link is created by Picturepark. Controlled vocabularies are used once again to improve metadata integrity.
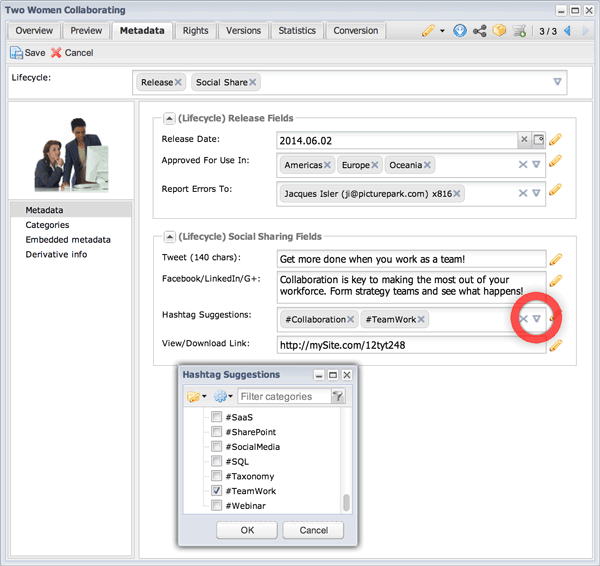
Classes are a great way to offer users the content they need for social sharing. Many users won’t know which hashtags to use, so you can provide suggestions using controlled vocabularies.
Lifecycle: Emergency Recall
If you ever need to take content out of circulation either temporarily or permanently, you can communicate that via metadata. (Picturepark can change the asset’s permissions based on this metadata, if you like.) Picturepark can automatically remove a class based on metadata values. So, you could have this class automatically removed on the Recall Expiration date, if one has been provided. (Embargoes can be conveniently handled this way too.)
Lifecycle Stage 5: A problem arises, so the Recall lifecycle class is added to the asset. Using the five new fields that appear, we describe the problem. If we know when the recall will expire (meaning the asset is once again safe to distribute), we can add that date in the field provided. Without an expiration data, the recall remains in effect until the class is manually removed by an authorized user.
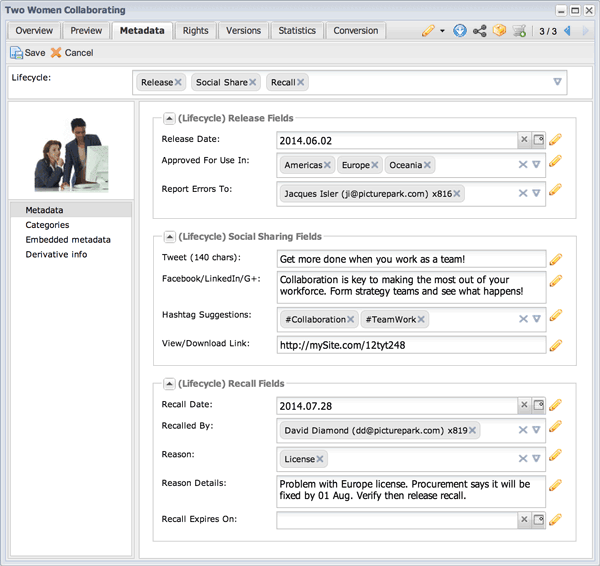
By grouping recall fields into their own class, the fields won’t appear on content that has not been recalled. Further, you have a single failsafe mechanism for finding all recalled assets just by searching for all assigned to this class.
Lifecycle: Archive
When the content has outlived its usefulness, you can add a class to provide values for Archive Date, Reason and other values you need. Note that this “Reason” field is not the same as the Emergency Recall “Reason” field. Picturepark knows the difference between fields assigned to different classes, even if they share the same field label.
Lifecycle Stage 6: The art director no longer likes the edits made to the content. Worse, a required license could not be renewed. The decision is made to archive the content. All classes are removed and the Archive class is added. Three fields appear that we use to describe our reason for archiving the content. By using controlled vocabularies for the Reason field, we ensure that data is reportable.
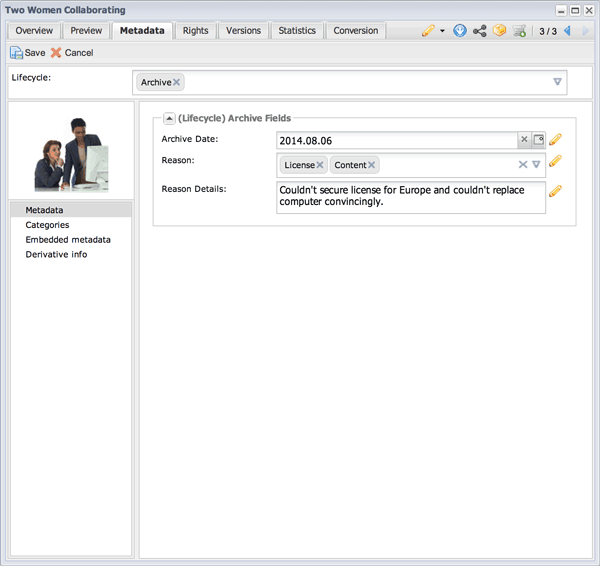
It’s up to you whether or not you want to remove previously assigned classes. In order to avoid potential confusion because the Release and Archive classes are both assigned, you can make those classes “exclusive” to one another so that only one can be assigned at a time.
Summary
Content lifecycle management is only one of the advanced digital asset management capabilities Adaptive Metadata offers. Simultaneously (or instead), you could use Picturepark classes to:
- Provide different metadata schemas to different stakeholders. (Example: Provide research teams with the technical metadata they need, while sales teams see market-focused metadata only.)
- Layer metadata schemas for clarity and separation. (Example: Dublin Core metadata on one layer and internal production metadata on another.)
When considering the value Adaptive Metadata offers for lifecycle management, keep in mind that each asset in Picturepark has its own class assignments. This is why Recall fields won’t appear on assets that have not been recalled, and why you can reduce your metadata schemas to only those values that are relevant for that asset during that stage of its lifecycle.
Note also that these class assignments are not at all related to file format. Though this example uses an image, the very same conditions could apply to Word or PowerPoint documents, video or any other file type. Filtering metadata field visibility based on file formats or other inflexible conditions is not Adaptive Metadata. As you’ve learned from this example, Picturepark Adaptive Metadata is both an additive and subtractive technology that uses “building blocks” of metadata groups to define a given piece of content’s ultimate metadata schema.
A note about localization: Each metadata value and field label provided by a class can be localized into multiple languages. So, while classes could be used for multi-language support, Picturepark’s built-in support for multiple languages is a better option for this because it considers the user’s connected language for search and user interface elements.
Image courtesy of sattva / FreeDigitalPhotos.net