By Matthew Jones • Jun 13, 2019
In this part of the FOFA blog series, we will cover an area that lies right at the heart of good content management, an area that sets out good foundations not only for the present but also far into the future: information architecture and data models. If you are interested to learn more about who FOFA are, read their backstory.
FOFA, in planning out the structure of their information architecture, designed it to meet a series of specific goals. For this, they started out simply by studying one key area to good modelling for information architecture: they looked at what kinds of content types they would be managing, focusing first and foremost onto product data of any type, file-based and fileless.
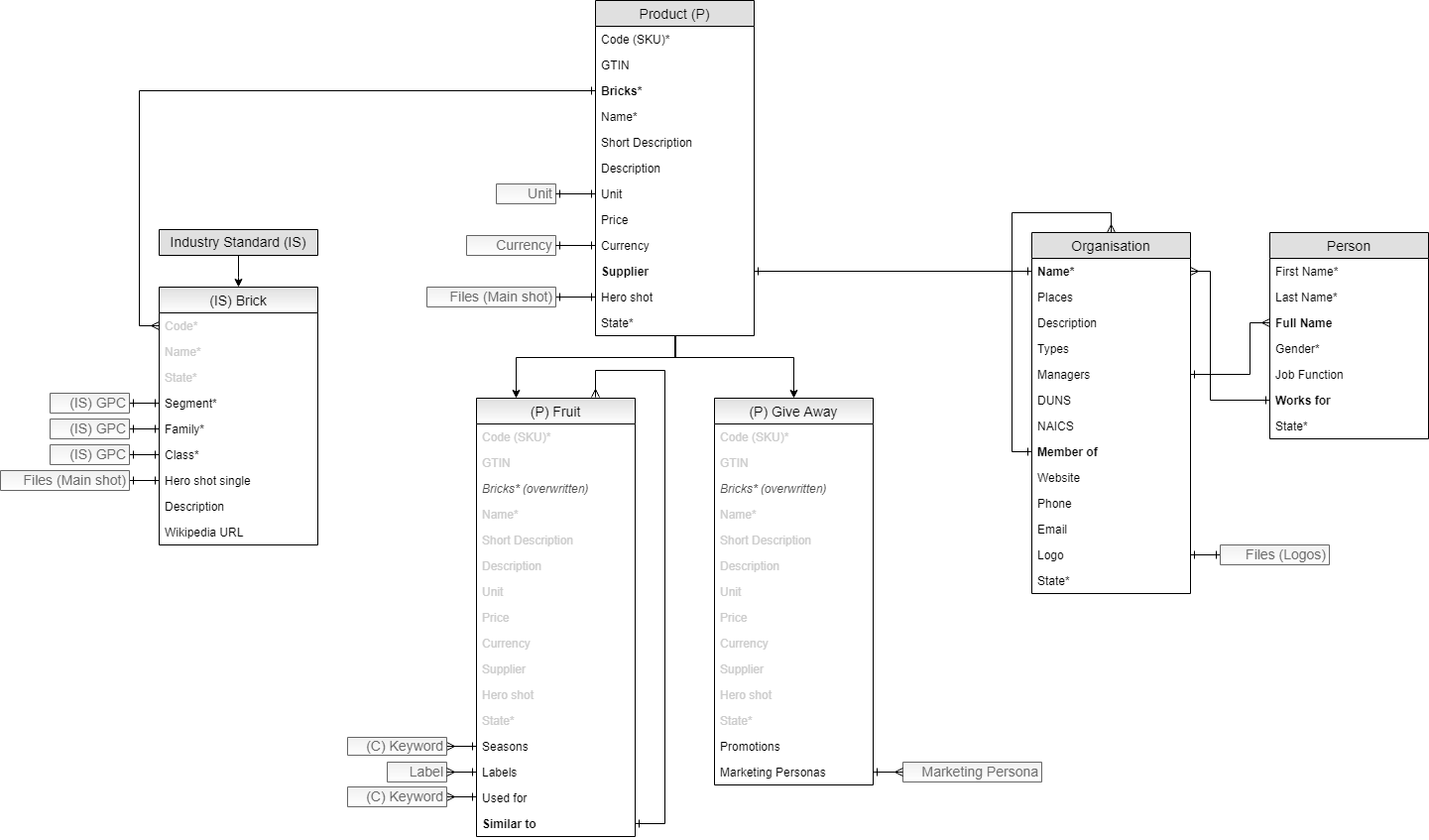
The kind of content types that they were to be managing didn’t mean filetypes, instead FOFA’s core team when focusing on data modelling looked at the types of content itself – this included different selections of content that included but was not limited to: product content such as close-up shots of organic fruit, event content such as information about cooking courses, it included company content such as images of employees out in the farm fields and brand logos.
The next step was to adopt a specific structure of schemas for usage across content types and effective data modelling. For this, FOFA reviewed those schemas that can be found on schema.org – these include definitions of areas such as Person, Organisation and Event among others. However, like with almost all – a “one size fits all” approaches, it didn’t fit perfectly with specific or niche content and as a result, some schemas required customisation.
Like with almost all – a “one size fits all” approaches, it didn’t fit perfectly with specific or niche content and as a result, some schemas required customisation.
FOFA understood that bets possible adherence to standards was key in order to ensure data interoperability further down the road. So it early on included a range of different standardization systems for the food industry, and others. This included NAICS for classification of the different businesses by economic activity, GTIN as a global product identifier and brick product codes for universal product categorization, all part of the Global Product Classification (GPC) system of GS1, a global standards organization.
A well-planned taxonomy is right at the heart of FOFA’s information architecture planning too. They adapted an established thirty-thousand term taxonomy to which they added their customized dictionary, which provided more specific terms in their precise field of organic produce.
When it came to time-saving capabilities, FOFA were keen to weave some of this into their information architecture too: primarily in the form of auto-tagging. For this purpose, they took advantage of Picturepark’s inbuilt integration with Clarifai, this allowed them to work through and tag images at a far quicker pace.
Through Picturepark’s support of multidimensional metadata and semantic relationships, all this data could be better connected together, ultimately resulting in content system that dealt with a much broader set of information as originally intended by FOFA.
