von Matthew Jones • Okt. 22, 2018
Taxonomien sind ein unglaublich wichtiger Teil des Content Management: Sie bilden das Fundament für ein effizientes Content-Management-System. Möglicherweise haben unsere Leser bereits über die Verwendung von KI im Zusammenhang mit Content Management gehört. In diesem Blogbeitrag geben wir eine kurze und kostenlose Einführung in die Erstellung einer komplett neuen Taxonomiestruktur mithilfe künstlicher Intelligenz (KI).
Die Bilderkennung in einem neuen Licht betrachten
Man könnte sich fragen, woher solch ein Konzept stammt, zumal die sonst übliche Verwendung von Auto-Tagging hierbei quasi “auf den Kopf gestellt” wird. Anstatt eine bereits existierende Taxonomie um zusätzliche Tags zu erweitern, kann das Auto-Tagging auch benutzt werden, um eine Taxonomie von Grund auf neu zu erstellen. Zunächst beschäftigen wir uns damit, warum dieses Vorgehen für eine Person oder ein Unternehmen sinnvoll sein kann. Danach erklären wir, wie das im Einzelnen funktioniert.
Nach über 2 Jahrzehnten Erfahrung im Content-Management ist uns hier bei Picturepark ziemlich klar, dass Taxonomien für CM-Neulinge ziemlich einschüchternd wirken können. Neue Benutzer haben dadurch oft eine Tendenz zum “Überplanen” ihrer Taxonomien, wodurch diese übermäßig strukturiert sind. So kann es leicht passieren, dass sich die Taxonomie zu sehr an der eigenen Perspektive und Rolle im Unternehmen orientiert. Oder aber man versucht, die Taxonomie aus einer imaginären Sichtweise oder einer Perspektive, die ihrer Meinung nach für das gesamte Unternehmen passt, zu erstellen.
Als Ergebnis sind viele Taxonomien nicht voll funktionsfähig, weder in der Gegenwart, noch in der Zukunft. Häufig werden neue Tags hinzugefügt, die sich aber meistens nach den eigenen Bedürfnissen richten. So kann es schnell passieren, dass die eigene Taxonomie in Unordnung gerät und eine grosse Zahl an Duplikaten enthält. Das führt dazu, dass andere sie nur schwer benutzen können und die Einarbeitung neuer Mitarbeiter erschwert wird.
Erst erstellen, dann erweitern
Die Erstellung einer Taxonomie mit Auto-Tagging-Werkzeugen bedeutet, dass Benutzer basierend auf tatsächlich in den Inhaltsbibliotheken vorliegenden Inhalten sofort ein Vokabular erstellen können. Im Gegensatz dazu steht die Erzeugung eines Vokabulars anhand einer Vorstellung oder Vorhersage der möglicherweise zukünftigen Inhalte. Hieraus entsteht etwas sehr Wertvolles: eine Taxonomie, die ausschliesslich auf “harten Daten” basiert, die im aktuellen Moment tatsächlich vorhanden sind.
Natürlich können Benutzer anhand dieser Methode ihre Taxonomie anpassen und erweitern, wenn diese im Laufe der Zeit wächst. Dies geschieht entweder durch Auto-Tagging oder manuelles Hinzufügen von Strukturen. Das Grundkonzept ist die Erstellung einer grundsätzlichen Taxonomie, auf die aufgebaut und die weiter entwickelt werden kann.
Vorbereitungen
Durch die fortschrittlichen Fähigkeiten des Auto-Tagging kann eine grundsätzliche Taxonomie schnell und einfach erstellt werden. Hierfür werden nur die folgenden Dinge gebraucht:
- Eine bereits vorhandene Basis von Beispielbildern.
- Einen bereitwilligen DAM-Hersteller, -Entwickler oder Zugriff auf einen Online-Tagging-Service.
- Eine Testgruppe, die hilft, das von der KI erzeugte Taxonomievokabular zu verfeinern.
Vor der Erstellung der Taxonomie ist es wichtig, sich über die Menge der Beispielbilder klar zu werden. Zuerst muss entschieden werden, welche und wie viele Bilder verwendet werden sollen. Wie bei jeder Art der Forschung, sollte auch hier klar sein, das eine grosse Zahl von Beispieldaten eine breitere Basis für die eigenen Experimente bedeutet. Dadurch haben Anomalien geringere Auswirkungen, was die Fehlergrenze (“margin of error”, wie die Statistiker sagen) herabsetzt.
Natürlich sollte dies in einem gesunden Verhältnis zu Dingen wie der investierten Zeit und den vorhandenen passenden Bildern stehen. Es ist besser, mit einer kleineren Menge an Beispieldaten zu arbeiten, als das Taxonomie-Vokabular mit einer Menge unnötiger Begriffe zu verzerren. Ein paar hundert Beispielbilder sollten es aber mindestens sein.
Eine Methode für die Taxonomie-Erstellung wählen
Im Interesse der Vielseitigkeit behandeln wir hier drei verschiedene Methoden der Taxonomie-Erstellung mit Auto-Tagging-Werkzeugen:
Methode Eins: Verwendung eines DAM-Providers mit integrierter KI.
Methode Zwei: Direkte Verwendung eines KI-Providers anhand einer Demoversion eines webbasierten Bilderkennungsdienstes.
Methode Drei: Erstellung eines kleinen API-Clients. Diese Methode benötigt etwas Entwicklungszeit, entweder durch den Anwender selbst oder, wenn diesem das Programmieren nicht so liegt, durch das Engagieren eines Entwicklers für ein paar Arbeitsstunden.
Methode Eins: Verwendung eines DAM-Systems mit KI
Die meisten DAM-Systeme besitzen eine integrierte KI-Funktionalität. Picturepark besitzt beispielsweise einen eingebauten Clarifai-Connector,
der ein automatisches Tagging des Contents ermöglicht. Für
Interessierte richten wir auf Anfrage gerne einen kostenlosen
Probeaccount ein, um den Prozess anzustossen. Dafür müssen nur die nötigen Details hier eingegeben werden.
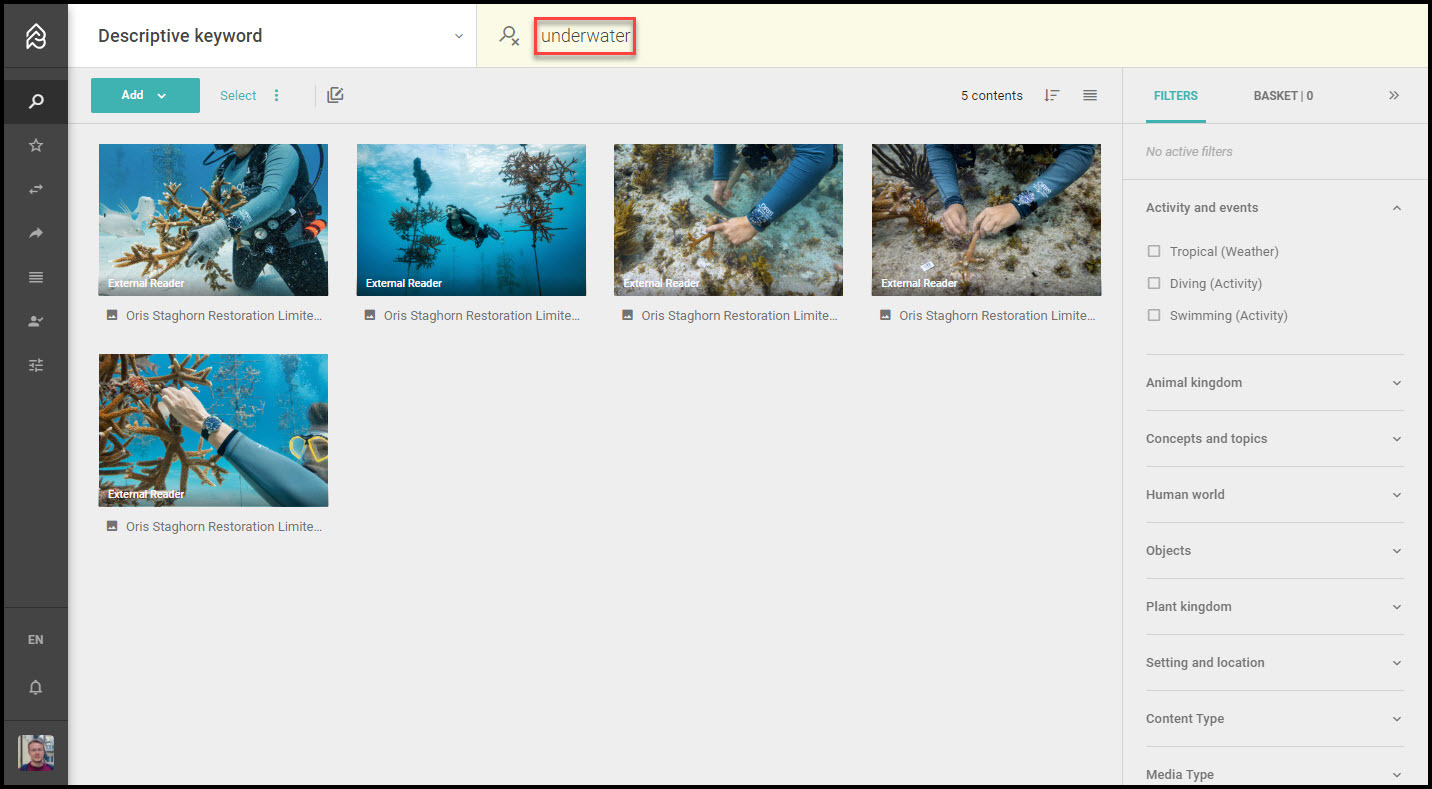
Die Verwendung eines DAM-Providers wie Picturepark bedeutet auch den Zugriff auf Features, die die Erstellung eines Taxonomie-Vokabulars stark vereinfachen. Hierzu gehört eine native Option für den Export von Keywords basierend auf der Bildauswahl. Warum das wichtig ist, erklären wir gleich.
Methode Zwei: Verwendung eines KI-Web-Demos
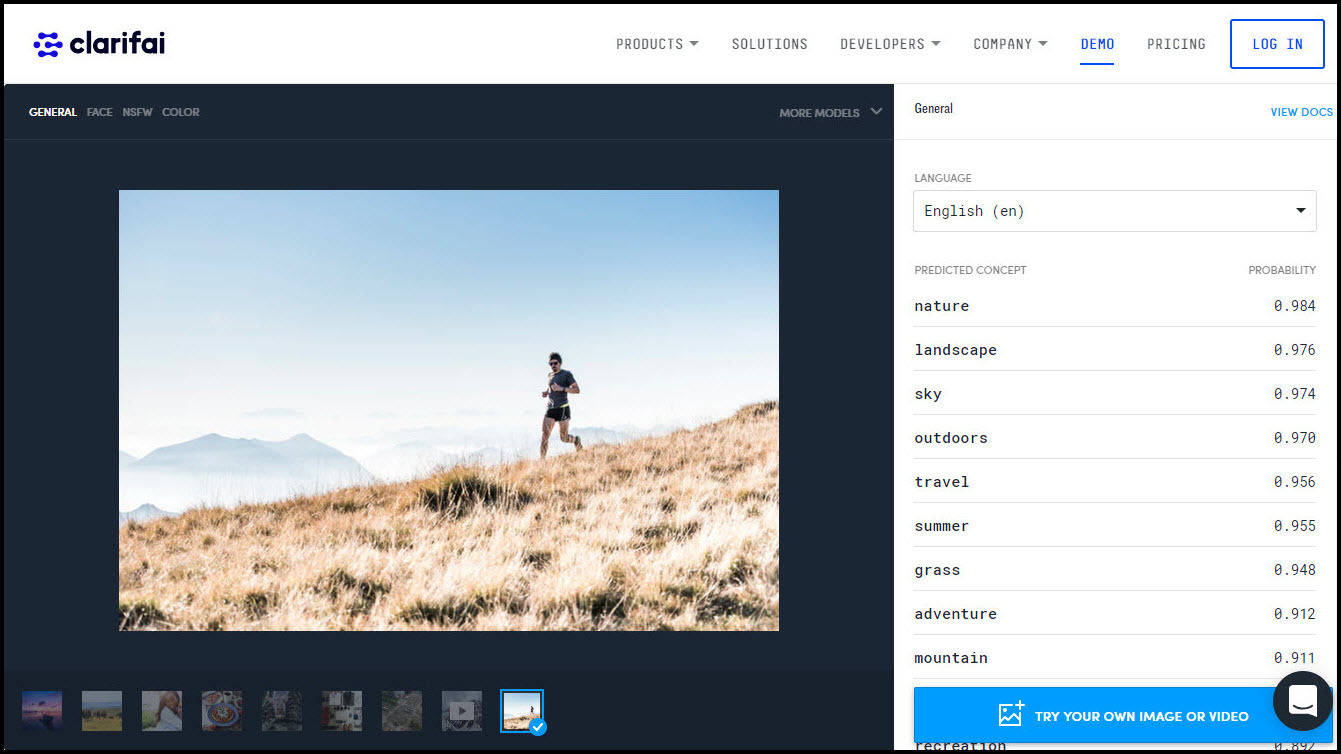
Entscheidet man sich für den direkten Weg zu einem KI-Provider mit einem Web-Demo, müssen verschiedenen Optionen berücksichtigt werden. Soll es einer der Anbieter sein, mit denen wir hier bei Picturepark regelmäßig zusammenarbeiten, so führt der einfachste Weg zur Clarifai-Demoseite. Daneben gibt es natürlich auch andere kostenlose Online-Demos wie beispielsweise von Imagga und Microsoft Azure.
Steht nur eine geringe Anzahl von Beispielbildern zur Verfügung, ist die Verwendung dieser Werkzeuge möglicherweise nicht die beste Wahl für den Aufbau eines Taxonomie-Vokabulars. Der Grund ist, dass es sich um browserbasierte Demoversionen handelt. Es gibt keine Option, grosse Mengen an Keywords zu importieren. Meist bleibt hier nur Copy und Paste als Möglichkeit.
Methode Drei: Einen API-Client erstellen
Entscheidet man sich, einen eigenen API-Client zu erstellen, gibt es auch hier eine Reihe verschiedener Optionen. Bei diesem Weg kann man neben der Clarifai-eigenen API auch andere KI-Provider einsetzen, die kostenlose API-Keys für die Entwicklung bereitstellen. Hierzu gehören Google Vision, DeepAI, Amazon Rekognition und CloudSight. Allerdings sollte man beachten, dass die kostenlosen Versionen der API-Keys in vielen Dingen beschränkt sind und Vollversionen kostenpflichtig sind. Daher sollte man genau überprüfen, was für den gewünschten Einsatzzweck am besten funktioniert. Auch das Kleingedruckte der einzelnen Provider sollte genau gelesen werden bevor man sich an die Entwicklung macht, da die Datenschutzbestimmungen sehr unterschiedlich sein können.
Zwei einfache Schritte zur Erstellung der eigenen KI-Taxonomie
Das Vorgehen ist einfach und besteht nur aus zwei Schritten:
1. Die Keywords zusammenstellen: Die Zusammenstellung von Keywords anhand einer der oben genannten Methoden.
2. Beginn der Textanalyse: Die Verwendung eines Werkzeugs zur Textanalyse zur Priorisierung und Entfernung von Duplikaten.
1. Die Keywords zusammenstellen
Taxonomie-Struktur bilden sollen. Hierfür werden alle Bilder durch den Bilderkennungs-Provider verarbeitet und die erstellten Keywords gespeichert. Wird Picturepark oder eine selbst erstellte API verwendet, kann dies über einen Export geschehen. Bei einer browserbasierten Demoversion müssen die Keywords manuell kopiert werden. Danach sollten die gesammelten Informationen in einer Tabelle gespeichert werden, da für den zweiten Schritt eine strukturierte Liste gebraucht wird.
Beim Durchsehen der Keywords wird man feststellen, dass einige Bilder falsch erkannt wurden. Diese sollten beim Untersuchen der Keyword-Frequenz jedoch ausgefiltert werden. Ausserdem enthält die Liste möglicherweise noch viele Duplikate. Aber keine Sorge: Im nächsten Schritt werden die gesammelt Daten auf die wirklich wichtigen Treffer reduziert.
2. Beginn der Textanalyse
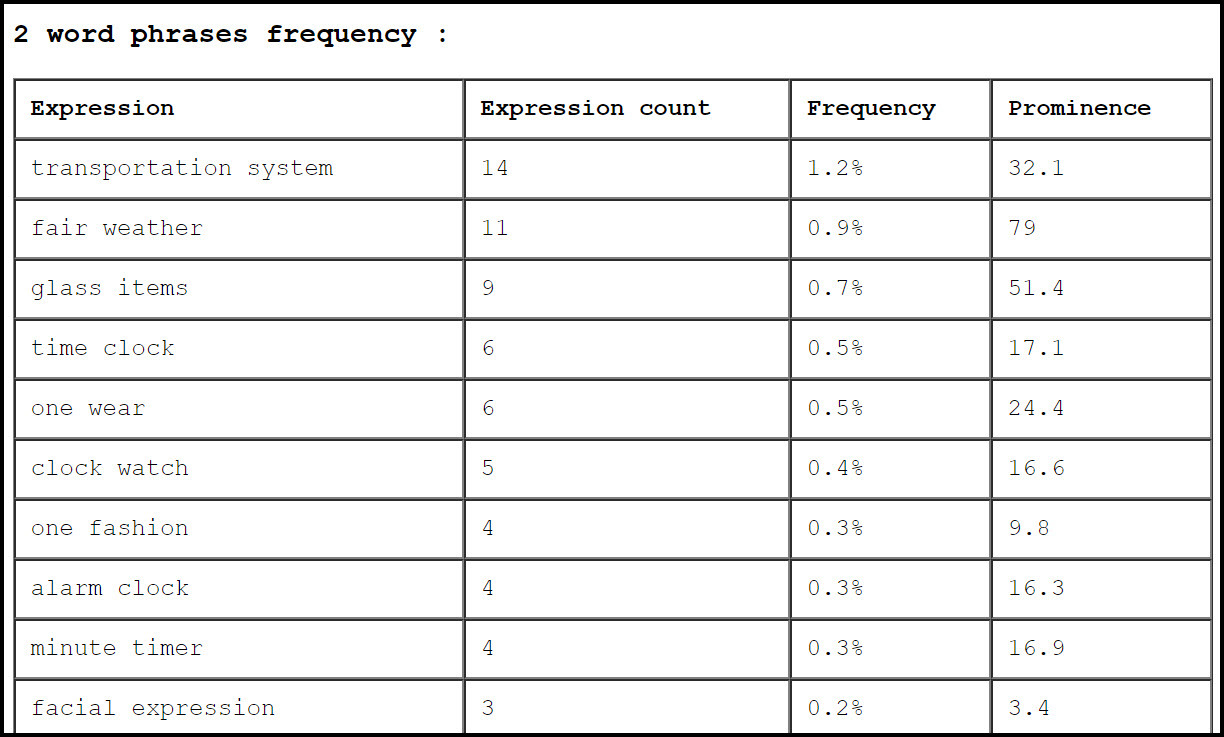
Für die Textanalyse verwenden wir ein kostenloses Tool namens Textalyser. Hiermit können die Keywords sortiert werden, um herauszufinden, welche Begriffe am häufigsten vorkommen. Das Konzept besteht in der Erstellung einer zweiten Begriffsliste, idealerweise einer neuen Tabelle, die direkt für die Taxonomie verwendet werden kann.
Nachdem die Liste der Keywords in Textalyser kopiert wurde, erhält man eine Ergebnisseite. Auf dieser Seite sind zwei Bereich besonders wichtig: “Frequency and top words” und “2 word phrases frequency”. Bevor die Daten aus diesen Bereichen in eine neue Tabelle kopiert werden, ist es wichtig, sich zuerst die Ergebnisse anzusehen und das prozentuale Vorkommen der Begriffe zu untersuchen. Anhand eines Prozentwertes kann man schnell erkennen, wie häufig eine Phrase oder ein Wort gelistet wurde. Ausserdem muss ein Prozentwert bestimmt werden, unterhalb dessen die Ergebnisse nicht mehr relevant sind. Dies kann man als Grenzwert verwenden, an dem man mit dem Kopieren aufhört. In der unten stehenden Abbildung sieht man ein Beispiel für die prozentualen Anteile der einzelnen Begriffe.
Hierbei gibt es keinen “korrekten” Prozentwert, der als Hinweis für den Grenzwert dienen kann. Man muss selbst entscheiden, ab welchem Punkt die Ergebnisse nicht mehr relevant sind. Ein zu niedriger Prozentwert bedeutet, dass die Ergebnisse zu viele Anomalien und falsche KI-Treffer enthalten. Zudem sollte man nicht vergessen, dass nicht verwendete Begriffe auch nachträglich noch hinzugefügt werden können. Man sollte also keinen zu niedrigen Grenzwert verwenden, nur damit auch diese Begriffe berücksichtigt werden.
Dieser Schritt ist eher eine Kunst als eine Wissenschaft. Daher ist es eine gute Idee, hier seine interne Testgruppe zur Kontrolle in den Prozess einzubeziehen. Einige DAM-Systeme, Content-Management- oder Intranet-Software können Informationen aus Suchabfragen exportieren. Anhand dieser Informationen ist es möglich, die KI-generierte Taxonomie direkt mit den Ergebnissen einer menschlichen Testgruppe zu vergleichen. Falls in diesem Bereich Hilfe gebraucht wird, ist es möglicherweise sinnvoll, einen Taxonomie-Profi zu engagieren. Weitere Informationen hierzu gibt es am Ende dieses Blogartikels.
Sobald die Daten in eine neue Tabelle kopiert wurden, hat man bereits das Rückgrat der eigenen Taxonomie. Diese kann für verschiedene Zwecke verwendet werden: die Verbesserung durch das Hinzufügen einer Synonym-Hierarchie (für die unser Beispieltaxonomie-Download hilfreich sein könnte), das Notieren interessanter Beobachtungen über den Content oder sogar die Erstellung einer eigenen Instanz eines Content-Management-Systems.
Eine frische Sicht auf Taxonomien
Taxonomien können oft problematisch sein und neue Benutzer gerade beim Einstieg ins Content Management abschrecken. Wir wollen mit diesem Blogartikel zeigen, dass die Erstellung einer einfachen Taxonomie nicht automatisch viel Arbeit, Geduld oder Veränderungen bedeutet. Taxonomien sind nicht statisch; sie wachsen und passen sich im Laufe der Zeit an den veränderten Content an.
Hierbei kann die Bilderkennung nicht nur für die üblichen Einsatzbereiche verwendet werden. In unserem Fall haben wir die übliche Verwendung künstlicher Intelligenz quasi umgekehrt, um anhand einer Sammlung von Beispielbildern eine eigene Taxonomie zu erstellen. Danach kann die neue Taxonomie als Framework für manuelle Erweiterungen dienen oder einem Taxonomisten zur weiteren Verbesserung übergeben werden.
Wenn Sie mit einem Taxonomie-Experten Kontakt aufnehmen möchten, mehr über das Thema erfahren oder DAM-Systeme im Allgemeinen erfahren möchten, sind Sie bei unserem DAM Guru Program (Englisch) genau richtig.
