von Picturepark Communication Team • Sept. 21, 2017
Blog aus einer Reihe von Seiten, welche die Funktionalitäten der Picturepark Content Platform darstellen.
Nur relevante Metadaten
Jedes Stück Content ist unterschiedlich. Beispielsweise müssen für ein Event andere Informationen (Metadaten) getrackt werden, als für finanziellen oder produktbezogenen Content. Genauso braucht Content für die Veröffentlichung andere Metadaten — die z.B. vorgeben, wo er veröffentlicht werden soll — als Content, der archiviert werden muss.
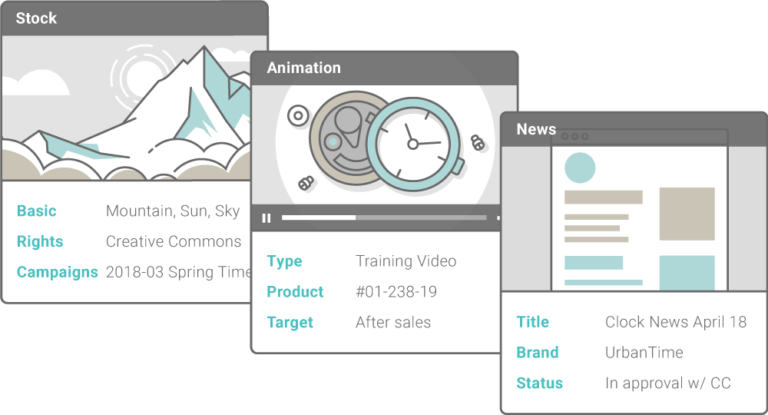
Mit Picturepark können verwandte Metadaten-Felder in Layers gruppiert werden, die jederzeit leicht hinzugefügt oder entfernt werden können, und sich so an Typ, Lifecycle, Zweck und andere Eigenschaften des Contents anpassen. Diese Technologie namens Adaptive Metadata™ verbessert die Beschreibung, Kontrolle und das Tracking des Contents, weil immer nur die gerade benötigten Metadaten verwaltet oder angezeigt werden müssen.
Kontrollierter Workflow
Adaptive Metadata eignet sich bestens, um den Lifecycle von Content zu tracken und komplette Workflows zu verwalten. Muss beispielsweise ein Hersteller von Produkten Content über dedizierte Portale zu verschiedenen Märkten routen, kann all dies über Adaptive Metadata angestossen, kontrolliert, und dabei genau nachverfolgt werden, was gerade passiert.
Nehmen wir beispielsweise die folgenden Schritte:
- Entwurf — Der Content wird erstellt.
- Veröffentlichung — Der genehmigte Content wird veröffentlicht.
- Archivierung — Der Content wird nicht länger gebraucht und wurde archiviert.
Ist der Content beispielsweise veröffentlicht, haben die Benutzer vermutlich folgende Fragen:
- Wer hat den Content genehmigt?
- Wo wurde der Content ausserdem noch veröffentlicht?
- Wie lange wird der Content veröffentlicht sein?
Mit Adaptive Metadata kann man nach Bedarf ein Layer aus Metadaten-Feldern für eine bestimmte Lifecycle-Phase erstellen. Sobald sich die Phase ändert, werden nicht mehr benötigte Felder entfernt, oder innerhalb des Layers anhand von Feldsets organisiert. Dies kann von jedem Benutzer mit den nötigen Rechten oder auch automatisch erfolgen.
Layer-Rechte
Picturepark kann verschiedene Metadata-Layers zur Verfügung stellen, abhängig von der Zielgruppe oder einem externen Business-System, das den Content verwendet, bzw. bereitstellt. Für jedes Adaptive Metadata Layer können eigene Benutzerrechte definiert werden, damit empfindliche Metadaten nur autorisierten Personen zugänglich sind.
So kann man Kunden andere Metadaten anzeigen, als normalen Mitarbeitern. Vertriebsmitarbeiter können Informationen zu Pitches sehen, aber nicht die gleichen Änderungen vornehmen wie ein Content Editor, und nur der Produktmanager kann den Content für die Verföffentlichung genehmigen.
Beispiele für Adaptive Metadata
Unten sieht man ein paar Beispiele für Adaptive Metadata-Layers, die zum standardmässigen Lieferumfang jeder neuen Picturepark Content Platform gehören. Die Layers können ganz nach Bedarf verändert und neu erstellt werden.
- Basis-Informationen: Basis-Informationen zum Speichern allgemeiner Metadaten wie Titel und Beschreibung des Contents.
- Beschreibende Stichwörter: Detaillierte beschreibende Metadaten, unterteilt in Konzepte oder Domains mit einem kuratierten Standard-Vokabular von ca. 30.000 Begriffen in mehreren Sprachen.
- Event-Informationen: Event-bezogene Metadaten zum Speichern von Event-Name, Veranstaltungsort, Datum und weiteren Details.
- Informationen zur Lifecycle-Phase: Status im Laufe des digitalen Lebenszyklus wie “Entwurf”, “Veröffentlicht”, “Archiviert” mit zusätzlichen Details zur jeweiligen Phase.
- Produkt-Informationen: Produktname und Links zu Produktdetails, inklusive aller Attribute.
- Rechte & Verwendung: Informationen zu Lizenztyp(en), erlaubte Verwendung, Copyright-Inhaber und Copyright-, bzw. Verwendungshinweise.
- Medien-Informationen: Für den Content-Typ spezifische Informationen wie beispielsweise “Medientyp: Produktfoto” und dessen Quelle.
- Kampagnen-Informationen: Name, Dauer und Verwendungsinformationen für eine Kampagne.
- Corporate-Informationen: Informationen wie Produktionsstätte und Mitarbeiter.
Stacking von Metadaten
Manchmal auch als die “kleine Schwester von Adaptive Metadata” bezeichnet. So genannte Feldsets erweitern ein Metadaten-Layer innerhalb der Picturepark Content Platform um Sätze strukturierter Daten.
Das kann hilfreich sein, wenn Metadaten historisiert werden sollen oder Content mit bestimmten Begriffen getaggt werden soll, welche nicht Teil eines allgemeinen Vokabulars sein sollen. So kann beispielsweise eine detaillierte Verwendungshistorie des Contents erstellt werden, die über eine API aus externen Systemen gespeist wird. Content kann mit Adressen oder bestimmten Personen getaggt werden, ohne sie hierfür zu einer mehrdimensionalen Liste hinzufügen zu müssen, während bei der Eingabe der Person oder Adresse trotzdem ein bestimmtes Format verwendet werden muss.
Ausserdem kann die Verbindung aus Feldsets und Workflow-Automation ein sehr mächtiges Werkzeug zum Tracken von Lifecycles, Workflow-Status und dem Anstossen bestimmter Tasks sein.
